account mapping что такое
Мэппинг в бюджетировании. Что это, и зачем он нужен?

Если в процессе подготовки данных для бюджетирования задействовано более одного человека, то встает вопрос о том, как сделать так, чтобы при обработке первичных данных соблюдалась последовательность и единообразие, чтобы один набор параметров всегда был сопоставлен одной статье бюджета, а не так, как по какой-то причине захотелось сегодня пользователю. Здесь на помощь приходит мэппинг
Мэппинг – это сопоставление, определение связей и соответствия между различными объектами системы. Говоря по-русски, это картирование, когда вы составляете «карту системы», описываете маршрут процесса получения данных. Разберем сегодня, как этот инструмент пригодится в бюджетировании.
Система бюджетирования представляет собой один из контуров учета, представление и компоновка данных в котором может отличаться от их представления в оперативном и регламентированном контурах. В то же время система бюджетирования строится на том же наборе исходных данных, что и регламентированный и оперативный учет.
Информационная потребность руководства в управленческой информации может быть существенно шире, чем, например, данные, предоставляемые в рамках бухгалтерской и налоговой отчетности. Структура бюджетов, состав и группировка статей бюджетирования может отличаться от, например, отчета о финансовых результатах или оборотно-сальдовой ведомости в регламентированном учете. Статьи бюджетов – это отдельный от статей расходов, доходов, денежных средств и иных справочник.
Состав статей бюджетов может быть огромным, в то время как бухгалтерии, например, для учета доходов и расходов достаточно тех статей, что представлены в отчете о финансовых результатах, или тех статей движения денежных средств, что представлены в отчете о движении денежных средств.
Для сохранения целостности данных, контроля, получения информации в требуемом виде используется механизм сопоставления или мэппинга данных оперативного учета данным бюджетирования.
Суть мэппинга:
Для каждой статьи бюджета нужно указать, на основе каких данных оперативного учета при каких условиях формируется значение по ней, при каких условиях происходит отражение фактических данных в бюджете, либо в каком случае срабатывает заложенный в бюджете лимит.
Соотношение между справочниками может быть различным. Одна статья бюджета может складываться из нескольких статей расходов, например. Или данные одной статьи расхода в бюджете могут быть разложены на несколько статей бюджетов.
Возможны ситуации, когда всё будет один к одному: одна статья бюджета равна одной статье первичного учета, например, расхода. Это нормально. Многие так работают. Просто очень часто это неэффективно.
Важно:
Мэппинг должен обеспечивать целостность данных, т.е. учет всех возможных вариантов комбинаций, сумма которых в бюджетировании будет равна сумме данных в оперативном и регламентированном учете с поправкой на заранее известные не учитываемые в каком-то из видов учета данные.
Если ваше множество данных по какой-то статьей включает А, Б и ещё что-то, то условия должны включить их все:
— например, вы для одной статьи выбираете «А», для второй статьи выбираете «Не А»;
— либо вы можете выбрать для одной статьи «А», для второй «Б», для третьей «Не А и Не Б».
Т.е. должна быть учтена вся совокупность данных.
Если вы выберете только А и Б, то получите дыру в части данных из области «ещё что-то…».
Пока попробуйте понять написанное, а в следующей статье разберем пример, чтобы было понятнее, что это за зверь такой.
Чернобровов Алексей Аналитик
Big Data Mapping: что такое маппирование больших данных

В этой статье рассмотрено, что такое маппирование больших данных, как это связано с Data Science, когда и как часто выполняется этот процесс, а также, какие программные инструменты позволяют автоматизировать Big Data mapping.
Что такое маппирование данных и где это используется
Представим, что в одной из корпоративных систем сведения о семейном положении сотрудника хранятся так, что «1» в поле «дети» означает их наличие. В другой системе эти же данные записаны с помощью значения «True», а в третьей – словом «да». Таким образом, разные системы для обозначения одних и тех же данных используют разные отображения. Чтобы привести информацию к единообразию, следует сопоставить обозначения одной системы обозначениям в других источниках, т.е. выполнить процедуру мэппинга данных (от английского map – сопоставление). В широком смысле маппирование – это определение соответствия данных между разными семантиками или представлениями одного объекта в разных источниках. На практике этот термин чаще всего используется для перевода или перекодировки значений [1].
Дисциплина управления данными, Data Management, трактует маппинг как процесс создания отображений элементов данных между двумя различными моделями, который выполняется в начале следующих интеграционных задач [2]:
Таким образом, маппирование данных представляет собой процесс генерации инструкций по объединению информации из нескольких наборов данных в единую схему, например, конфигурацию таблицы. Поскольку схемы данных в разных источниках обычно отличаются друг от друга, информацию из них следует сопоставить, выявив пересечение, дублирование и противоречия [3].
С прикладной точки зрения можно следующие приложения маппинга данных [4]:
В Big Data мэппинг выполняется при загрузке информации в озеро данных (Data Lake) и корпоративное хранилище (DWH, Data Warehouse). Чем Data Lake отличается от DWH, рассмотрено здесь. В этом случае маппинг реализуется в рамках ETL-процесса (Extract, Transform, Load) на этапе преобразования. При этом настраивается соответствие исходных данных с целевой моделью (рис. 1). В случае реляционных СУБД для идентификации одной сущности в разных представлениях нужно с ключами таблиц и настройкой отношений (1:1, *:1, 1:* или *:*) [5].
 Рис.1. Маппирование данных при консолидации таблиц
Рис.1. Маппирование данных при консолидации таблиц
В Data Science маппирование данных входит в этап их подготовки к ML-моделированию, когда выполняется формирование датасета в виде матрицы значений для обработки соответствующими алгоритмами. В частности, когда Data Scientist обогащает исходный датасет данными из сторонних источников, он занимается маппингом данных. Проводить процедуру дата мэппинга можно вручную или автоматически с помощью соответствующих подходов и инструментов, которые рассмотрены далее.
Особенности процесса дата мэппинга
На практике трудоемкость мэппинга зависит от следующих факторов [3]:
Облегчить процесс маппирования можно за счет метаданных – сведениях о признаках и свойствах объектов, которые позволяют автоматически искать и управлять ими в больших информационных потоках. В частности, если каждое приложение будет выполнять публикацию метаданных, что позволит создать их стандартизированный реестр, то маппинг будет полностью автоматизированным [2]. Однако в большинстве случаев процесс мапирования данных не полностью автоматизирован и состоит из следующих этапов [4]:
При работе с большими объемами данных выделяют 3 основных подхода к маппированию [2]:
Также стоит упомянуть полуавтоматическое маппирование в виде конвертирования схем данных, когда специализированная программа сравнивает источники данных и целевую схему для консолидации. Затем разработчик проверяет схему маппирования и вносит исправления, где это необходимо. Далее программа конвертирования схем данных автоматически генерирует код на C++, C # или Java для загрузки данных в систему приемник (рис. 3) [3].
 Рис. 3. Конвертирование схем данных в процессе мэппинга
Рис. 3. Конвертирование схем данных в процессе мэппинга
Далее рассмотрим, какие инструментальные средства реализуют вышеперечисленные подходы.
Инструменты маппирования больших данных
Как и большинство прикладных решений, все средства для маппинга данных можно разделить на 3 категории [6]:
Большинство перечисленных продуктов поддерживают все 3 подхода к маппированию: ручной (GUI и кодирование), data-driven и семантический. Однако, семантический мэппинг требует наличия реестров метаданных, что имеется далеко не в каждом предприятии. А публичные реестры метаданных, такие как национальные, отраслевые или городские репозитории [7] не всегда напрямую коррелируют, например, с задачами построения локального DWH. Но, наряду с открытыми государственными данными и другими публичными датасетами, их можно использовать в исследовательских DS-задачах.
При выборе конкретного инструмента для маппинга больших данных стоит учитывать следующие факторы:
Резюме
Итак, маппирование данных – это важная часть процесса работы с данными, в том числе и для Data Scientist’а. Эта процедура выполняется в рамках подготовки к ML-моделированию, в частности, при обогащении датасетов. В случае одноразового формирования датасета из нескольких разных источников сопоставление данных можно выполнить вручную или с помощью самописного Python-скрипта. Однако, такой подход не применим в промышленной интеграции нескольких информационных систем или построении корпоративных хранилищ и озер данных. Поэтому знание инструментов дата мэппинга пригодится как Data Scientist’у, так и Data Engineer’у. Наконец, сопоставление данных с целью избавления от дублирующихся и противоречивых значений входит в задачи обеспечения качества данных (Data Quality) [4]. В свою очередь, Data Quality относится к области ответственности стратега по данным и инженера по качеству данных. Таким образом, понимание процесса маппирования необходимо каждому Data-специалисту.
Маппинг данных из реляционной БД
Иногда возникают ситуации, когда решение задачи выборки данных из реляционной БД не укладывается в возможности используемой в проекте ОРМ, например, либо из-за недостаточной скорости работы самой ОРМ, либо не совсем оптимальных SQL запросов генерируемых ею. В таком случае обычно приходится писать запросы вручную.
Проблема в том, что данные из БД (в т.ч. в ответ на JOIN запрос) возвращаются в виде “плоского” двухмерного массива никак не отражающего сложную “древовидную” структуру данных приложения. Работать с таким массивом дальше крайне неудобно, поэтому требуется более-менее универсальное решение, позволяющее привести этот массив в более подходящий вид по заданному шаблону.
Решение было найдено, удобное и достаточно быстрое.
На сколько быстрое
Для оценки скорости работы библиотеки я собрал небольшой испытательный стенд на котором скорость работы моей библиотеки сравнивается со скоростью работы Eloquent. Для замеров использовался пакет phpbench.
Для того чтобы развернуть стенд у себя:
Здесь я использовал инструмент описанный в моей предыдущей статье.
Затем в меню выбираем: 1 Develop, затем: 1 Build, затем 2 Deploy and Up;
Затем запускаем тесты 5. Run tests
В базе 3000 книг. Результаты получились следующие:
benchEloquent — вытаскивает все книги с авторами с использованием Eloquent
benchEloquentId — вытаскивает определенную книгу с авторами с использованием Eloquent (10 раз)
benchProc — вытаскивает все книги с авторами с использованием библиотеки
benchProcId — вытаскивает определенную книгу с авторами с использованием библиотеки (10 раз)
Возможно приведенные тесты недостаточно репрезентативны, но разница заметна, как по времени выполнения, так и по расходованию памяти.
Как это работает
Далее, для примера (крайне простого), представим, что у нас имеется БД книг и авторов со следующей структурой.

Задача — вытащить все книги с их авторами.
Запрос будет выглядеть как-то так:
В ответ мы получим примерно такой массив данных.
| book.id | book.name | author.id | author.name |
| 1 | book1 | 2 | author2 |
| 1 | book1 | 4 | author4 |
| 1 | book1 | 6 | author6 |
| 2 | book2 | 2 | author2 |
| 2 | book2 | 3 | author3 |
| 2 | book2 | 6 | author6 |
| 2 | book2 | 7 | author7 |
Для этого немного изменим наш запрос:
Здесь мы в секции SELECT задали алиасы: для полей с данными о книгах алиасы с префиксом ‘book_’, а для полей с информацией об авторах с префиксом ‘author’.
Далее преобразуем ответ БД
$rows — ответ БД в виде массива объектов /stdClass()
$config — ассоциативный массив отражающий структуру данных итогового массива
Часть 2. Создание классов, маппингов и заполнение БД
В предыдущей части были рассмотрены виды связей (один-к-одному, один-ко-многим, многие-ко-многим), а также один класс Book и его маппинг-класс BookMap. Во второй части обновим класс Book, создадим остальные классы и связи между ними, как это было изображено в предыдущей главе в Диаграмме баз данных, расположившейся над подзаголовком 1.3.1 Связи.
Небольшое объяснение
public virtual ISet Genres < get; set; >
public virtual ISet Authors
Отношение многие-к-одному, один-ко-многим.
| Book | Series |
|---|---|
| References(x => x.Series).Cascade.SaveUpdate(); | HasMany(x => x.Books) .Inverse(); |
Метод References применяется на стороне «Многие-к-одному», на другой стороне «Один-ко-многим» будет метод HasMany.
Если сейчас запустить проект и посмотреть БД Bibilioteca, то появятся новые таблицы с уже сформированными связями.
Далее заполним созданные таблицы данными…
Для этого создадим тестовое приложение, которое будет сохранять данные в БД, обновлять и удалять их, изменив HomeController следующим образом (Ненужные участки кода комментируем):
Изменим представление следующим образом:
Маппинг для классов, у которых есть наследование.
А как маппить классы у которых есть наследование? Допустим, имеем такой пример:
В принципе, ничего сложного в этом маппинге нет, мы просто создадим один маппинг для производного класса, то есть таблицы Triangle.
После запуска приложения, в БД Biblioteca появится следующая (пустая) таблица
What is Account Mapping?
-5.png?width=1200&name=Copy%20of%20Q3%20Blog%20Images%20(1)-5.png "Copy%20of%20Q3%20Blog%20Images%20(1) 5.png?width=1200&name=Copy%20of%20Q3%20Blog%20Images%20(1) 5")
Although there has been a surge in account-based marketing (ABM) recently, the concept itself is actually nothing new. Most companies are already doing some form of an ABM strategy, even if it’s not entirely intentional or fully structured.
The beauty of an ABM strategy is that when it’s done correctly, it allows your sales process to be extremely customized and personalized for each prospect. This will lead to a better experience for both the prospect and your sales reps, which in turn, should lead to more closed-won deals.
There are a lot of moving pieces that go into ABM from setting up your team to building out your tech stack to measuring success. One of the most crucial components of any ABM strategy is account mapping.
What is Account Mapping?
Account mapping is the process of cataloging and organizing the people that work at a particular target account. This will be a physical representation of the way an organization is set up.
This process takes quite a bit of time from your reps but ultimately will dictate how successful your entire ABM strategy is for your company.
“You don’t need fancy software to do account mapping,” says Guido Bartolacci, Head of Demand Generation at New Breed. “It can be done as a flow chart or a spreadsheet or even a Google Doc.”
Account mapping should be completed before any targeting or outreach takes place because it will impact everyone that is involved with a target account from both marketing and sales and puts everyone in a better position to succeed.

How Account Mapping Improves Your ABM
Account mapping is the building block for your entire ABM strategy.
ABM aims to create a hyper-personalized experience for prospects at companies that are the best fit for your product or service. To enable that to happen, you need to know everything possible about that company.
From a sales perspective, account mapping will give your reps a clear picture of who they may encounter during the sales process as well as who may be involved in the decision-making process.
It allows the reps to accurately predict how the process will go and what the best path of sale is for that particular company. Finding the best path of sale will allow your reps to identify which individuals they should reach out to first as well as who they should loop in to have the smoothest sales cycle as possible. It also allows reps to anticipate any hurdles or roadblocks, enabling them to be fully prepared to handle issues if they do arise.
Account mapping focuses not only on information at the company level, but also on understanding each individual at that company. You will be able to better understand the pain points and challenges of the specific individuals at a company and adjust your outreach accordingly.
“That information will also allow you to basically rehearse the type of interaction you will have before you have it,” says Guido. “If you know their persona, their pain points and challenges, you can ask questions related to those. For instance, if you know who their boss is, you can ask ‘hey would it make sense to bring your VP into the conversation?’”
Without directly telling that prospect that you know how important the VP is in the end decision-making process, you can set the meeting up for success by already looping them into the conversation. This saves your sales rep time and effort and also makes that process smoother for the prospect.
What is Included in an Account Map?
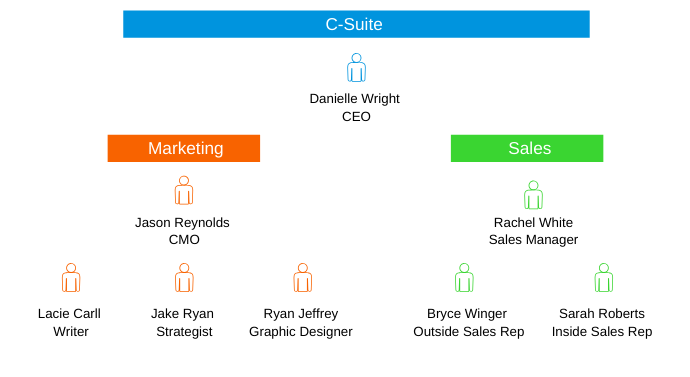
To start, you should break the organization down into both job level and function. Job level speaks to the hierarchy of an organization like manager, exec or VP. Function speaks to the different teams or roles at a company like marketing, human resources or finance.
“You would have your functions, like marketing, sales, service, operations and finance, for instance, across the top of your chart,” says Guido. “Then you would have your levels down the side on the left, like VP’s, managers, individual contributors.”
This will help you visualize the authority that an individual at the company has as well as their particular position related to their team as well. You then can associate individuals at a company with your buyer personas to better understand what they care about.
You don’t need to do account mapping for the entire company,
How to Find That Information
To source the information you need to build an account map, you will most likely want to invest in a data sourcing/enrichment software like ZoomInfo or EverString.
“The nice thing about those softwares is that while they don’t necessarily offer an account mapping feature per se, they will show you everyone in their system at a company including their role and department,” says Guido.
From there, you can add that info into your account map spreadsheet or chart appropriately.
In addition to providing name, title and team, databases like ZoomInfo or EverString sometimes will also offer contact information like email or phone number.
Linkedin is also a great free tool to either source that information yourself, validate the info you get from a data sourcing software or fill in the gaps that you can’t find in the platform itself.
“It should go without stating, but the information you gather during this process should not be used maliciously or in a creepy way,” says Guido.
All of this information should be used to help sculpt your outreach and the language you use to truly serve these prospects better. The entire idea of ABM is based on the fact that the companies you have chosen are truly the best fit for your company’s service or product, so finding the best way to make sure the individuals you interact with feel the same way is the ultimate goal.
Final Thoughts
An ABM strategy can yield great results for your business, and it’s also a great way to find new industries or target markets to break into. The key to ABM is to be prepared and have all your ducks in a row before getting started. This will ensure the process runs smoothly from the first interaction your prospects have with your brand to the last.
Account mapping is just one of the ten major steps to preparing for successful account-based marketing. Use our checklist to be sure you have all the other nine in line!

Weslee Clyde
Weslee Clyde is an inbound marketing strategist at New Breed. She is focused on generating results using inbound methods and is driven by the customer experience. When not at the office, you can find her binging a docu-series on true crime or perfecting her gluten-free baking skills.