глубинное машинное обучение и машинное обучение
Deep learning & Machine learning: в чем разница?
В чем разница между Deep learning и Machine learning? Насколько они похожи или отличаются друг от друга? Насколько они выгодны для бизнеса? Давайте разберемся!
Machine learning и Deep learning – это 2 подмножества искусственного интеллекта (ИИ), которые активно привлекают к себе внимание уже на протяжении двух лет. Если вы хотите получить простое объяснение их различий, то вы в правильном месте!
Прежде всего, давайте посмотрим на некоторые интересные факты и статистику Deep learning и Machine learning:
Любопытно? Теперь попытаемся разобраться, в чем на самом деле разница между Deep learning и Machine learning, и как можно использовать их для новых бизнес-возможностей.
Deep learning & Machine learning
Должно быть, вы имеете элементарное представление о Deep learning и Machine learning. Для чайников представляем несложные определения:
Machine learning для чайников:
Deep learning для чайников:
Подмножество машинного обучения, где алгоритмы создаются и функционируют аналогично машинному обучению, но существует множество уровней этих алгоритмов, каждый из которых обеспечивает различную интерпретацию данных, которые он передает. Такая сеть алгоритмов называется искусственными нейронными сетями. Простыми словами, это напоминает нейронные связи, которые имеются в человеческом мозге.

Взгляните на изображение выше. Это коллекция фотографий кошек и собак. Теперь предположим, что вы хотите идентифицировать изображения собак и кошек отдельно с помощью алгоритмов Machine learning и нейронных сетей Deep learning.
Deep learning & Machine learning: в каких случаях используется Machine learning
Чтобы помочь алгоритму ML классифицировать изображения в коллекции в соответствии с двумя категориями (собаки и кошки), ему необходимо сначала представить эти изображения. Но как алгоритм узнает, какой из них какой?
Deep learning & Machine learning: в каких случаях используется Deep learning
Нейронные сети Deep learning будут использовать другой подход для решения этой проблемы. Основным преимуществом Deep learning является то, что тут не обязательно нужны структурированные / помеченные данные изображений для классификации двух животных. В данном случае, входные данные (данные изображений) отправляются через различные уровни нейронных сетей, причем каждая сеть иерархически определяет специфические особенности изображений.
После обработки данных через различные уровни нейронных сетях система находит соответствующие идентификаторы для классификации обоих животных по их изображениям.

Таким образом, в этом примере мы увидели, что алгоритм машинного обучения требует маркированных/структурированных данных, чтобы понять различия между изображениями кошек и собак, изучить классификацию и затем произвести вывод.
С другой стороны, сеть глубокого обучения смогла классифицировать изображения обоих животных по данным, обработанным в слоях сети. Для этого не потребовались какие-либо маркированные/структурированные данные, поскольку она опиралась на различные выходные данные, обрабатываемые каждым слоем, которые объединялись для формирования единого способа классификации изображений.
Что мы узнали:
То, чего не было в примере, но стоит отметить:

Надеемся, приведенный пример и его объяснение позволили вам понять различия между Machine learning и Deep learning. Т.к. это объяснение для чайников, то здесь не употреблялись профессиональные термины.
Теперь пришло время забить последний гвоздь. Когда следует использовать глубокое обучение или машинное обучение в своем бизнесе?
Когда использовать Deep learning в бизнесе?
Когда использовать Machine learning в бизнесе?

Подведем итоги:
В связи с ростом различных технологий, предприятия в настоящее время ищут компании, занимающиеся технологическим консалтингом, чтобы найти то, что лучше для их бизнеса.
Развитие искусственного интеллекта также порождает рост услуг по разработке программного обеспечения, приложений IoT и блокчейна. В настоящее время разработчики программного обеспечения изучают новые способы программирования, которые более склонны к глубокому обучению и машинному обучению.
Различия между искусственным интеллектом, машинным обучением и глубоким обучением
Искусственный интеллект, машинное обучение и глубокое обучение уже сейчас являются неотъемлемой частью многих предприятий. Часто эти термины используются как синонимы.
Искусственный интеллект движется огромными шагами — от достижений в области беспилотных транспортных средств и способности обыгрывать человека в такие игры, как покер и Го, к автоматизированному обслуживанию клиентов. Искусственный интеллект — это передовая технология, которая готова произвести революцию в бизнесе.
Часто термины искусственный интеллект, машинное обучение и глубокое обучение используются бессистемно как взаимозаменяемые, но, на самом деле, между ними есть различия. Чем именно различаются эти термины будет рассказано далее.
Искусственный интеллект (ИИ)
Искусственный интеллект — широкое понятие, касающееся передового машинного интеллекта. В 1956 году на конференции по искусственному интеллекту в Дартмуте эта технология была описана следующим образом: «Каждый аспект обучения или любая другая особенность интеллекта могут быть в принципе так точно описаны, что машина сможет сымитировать их.»
Искусственный интеллект может относиться к чему угодно — от компьютерных программ для игры в шахматы до систем распознавания речи, таких, например, как голосовой помощник Amazon Alexa, способный воспринимать речь и отвечать на вопросы. В целом системы искусственного интеллекта можно разделить на три группы: ограниченный искусственный интеллект (Narrow AI), общий искусственный интеллект (AGI) и сверхразумный искусственный интеллект.
Программа Deep Blue компании IBM, которая в 1996 году обыграла в шахматы Гарри Каспарова, или программа AlphaGo компании Google DeepMind, которая в 2016 году обыграла чемпиона мира по Го Ли Седоля, являются примерами ограниченного искусственного интеллекта, способного решать одну конкретную задачу. Это его главное отличие от общего искусственного интеллекта (AGI), который стоит на одном уровне с человеческим интеллектом и может выполнять много разных задач.
Сверхразумный искусственный интеллект стоит на ступень выше человеческого. Ник Бостром описывает его следующим образом: это «интеллект, который намного умнее, чем лучший человеческий мозг, практически во всех областях, в том числе в научном творчестве, общей мудрости и социальных навыках.» Другими словами, это когда машины станут намного умнее нас.
Машинное обучение
Машинное обучение является одним из направлений искусственного интеллекта. Основной принцип заключается в том, что машины получают данные и «обучаются» на них. В настоящее время это наиболее перспективный инструмент для бизнеса, основанный на искусственном интеллекте. Системы машинного обучения позволяют быстро применять знания, полученные при обучении на больших наборах данных, что позволяет им преуспевать в таких задачах, как распознавание лиц, распознавание речи, распознавание объектов, перевод, и многих других. В отличие от программ с закодированными вручную инструкциями для выполнения конкретных задач, машинное обучение позволяет системе научиться самостоятельно распознавать шаблоны и делать прогнозы.
В то время, как обе программы — и Deep Blue, и DeepMind, являются примерами использования искусственного интеллекта, Deep Blue была построена на заранее запрограммированном наборе правил, так что она никак не связана с машинным обучением. С другой стороны, DeepMind является примером машинного обучения: программа обыграла чемпиона мира по Го, обучая себя на большом наборе данных ходов, сделанных опытными игроками.
Заинтересован ли Ваш бизнес в интеграции машинного обучения в свою стратегию? Amazon, Baidu, Google, IBM, Microsoft и другие уже предлагают платформы машинного обучения, которые могут использовать предприятия.
Глубокое обучение
Глубокое обучение является подмножеством машинного обучения. Оно использует некоторые методы машинного обучения для решения реальных задач, используя нейронные сетей, которые могут имитировать человеческое принятие решений. Глубокое обучение может быть дорогостоящим и требует огромных массивов данных для обучения. Это объясняется тем, что существует огромное количество параметров, которые необходимо настроить для алгоритмов обучения, чтобы избежать ложных срабатываний. Например, алгоритму глубокого обучения может быть дано указание «узнать», как выглядит кошка. Чтобы произвести обучение, потребуется огромное количество изображений для того, чтобы научиться различать мельчайшие детали, которые позволяют отличить кошку от, скажем, гепарда или пантеры, или лисицы.
Как уже упоминалось выше, в марте 2016 года искусственным интеллектом была достигнута крупная победа, когда программа AlphaGo DeepMind обыграла чемпиона мира по Го Ли Седоля в 4 из 5 игр с использованием глубокого обучения. Как объясняют в Google, система глубокого обучения работала путем комбинирования «метода Монте-Карло для поиска в дереве с глубокими нейронными сетями, которые прошли обучение с учителем на играх профессионалов и обучения с подкреплением на играх с собой».
Глубокое обучение также имеет бизнес-приложения. Можно взять огромное количество данных — миллионы изображений, и с их помощью выявить определенные характеристики. Текстовый поиск, обнаружение мошенничества, обнаружения спама, распознавание рукописного ввода, поиск изображений, распознавание речи, перевод — все эти задачи могут быть выполнены с помощью глубокого обучения. Например, в Google сети глубокого обучения заменили много «систем, основанных на правилах и требующих ручной работы».
Стоит отметить, что глубокое обучение может быть весьма «предвзятым». Например, когда была первоначально развернута система распознавания лиц Google, она помечала много черных лиц как гориллы. «Это пример того, что произойдет, если у вас нет афроамериканских лиц в вашем наборе обучения», сказала Anu Tewary, главный специалист по работе с данными Mint at Intuit. «Если у вас нет афроамериканцев, работающих над системой, если у вас нет афроамериканцев, тестирующих систему, то, когда ваша система сталкивается с афроамериканскими лицами, она не будет знать, как вести себя.»
Существует мнение, что тема глубокого обучения сильно раздута. Система Sundown AI, например, предоставляет автоматизированные взаимодействия с клиентами с использованием комбинации машинного обучения и policy graph алгоритмов без использования глубокого обучения.
Словарь: чем различаются машинное и глубокое обучение

В честь выхода обновлённой карты искусственного интеллекта Rusbase рассказывает об основных понятиях в сфере ИИ. В «словаре искусственного интеллекта» — ИИ, машинное и глубокое обучение и взаимосвязь между тремя терминами.
Что такое искусственный интеллект (Artificial intelligence)
Сложности в определении искусственного интеллекта связаны с неоднозначностью понятий «интеллект» и «думать». В наиболее распространенном значении «искусственный интеллект» можно описать как способность машины выполнять когнитивные функции, которые свойственны человеку — умение рассуждать, обучаться и совершенствоваться на основе предыдущего опыта, решать определенные задачи, взаимодействовать с окружающей средой.
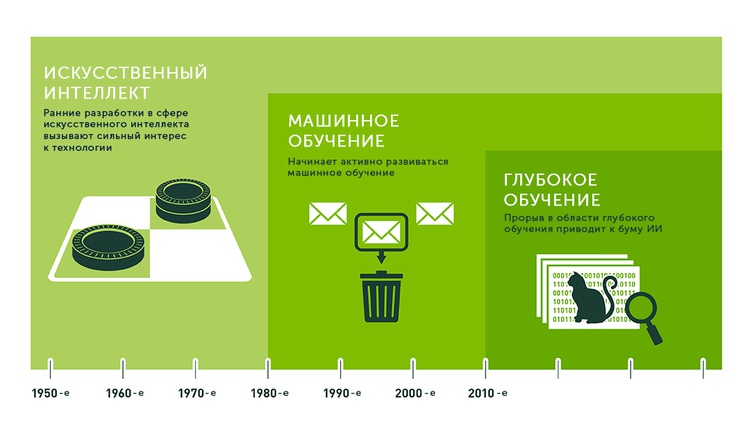
В качестве научной дисциплины ИИ появился ещё в 1956 благодаря профессору Джону МакКарти, который собрал группу ученых для работы над проектом по созданию «умных» машин, способных выполнять присущие человеку функции. Ранние разработки в области ИИ были направлены в основном на решение абстрактных логических и математических задач.
Расскажи, как цифровая трансформация изменила твой бизнес
Однако уже в 1962 программа на основе ИИ обыграла профессионального игрока в шашки, а в 1965 система Dendral, созданная в Стэнфорде, смогла определить химические структуры с помощью анализа масс-спектрограмм. Ранние успехи на этом поприще мотивировали ученых продолжать изучение ИИ.
Различают три вида ИИ в зависимости от его возможностей: ограниченный (способен решать только конкретный тип задач), общий (может обучаться любым навыкам и решать любые задачи) и сверхразумный (во всех сферах жизни превосходит человеческий). Единственный вид интеллекта, который пока удалось создать — ограниченный. Система, которая позволяет вам транскрибировать аудио в тексты, не может одновременно заказать пиццу или сыграть в шахматы — для каждой из этих задач необходима разработка отдельных алгоритмов.
Понятие «искусственный интеллект» само по себе ничего не говорит о методах, позволяющих машинам выполнять когнитивные функции. Один из таких методов — машинное обучение, которое начало активно развиваться в 1980-х гг, когда стало понятно, что более ранние методы не работают для обработки естественного языка или распознавания картинок.
Что такое машинное обучение (Machine learning)
Машинное обучение — это класс методов для решения задач искусственного интеллекта. Алгоритмы машинного обучения распознают паттерны в больших массивах данных и используют их для самообучения. Каждый новый массив данных позволяет алгоритмам совершенствоваться и адаптироваться в соответствии с полученной информацией, что позволяет постоянно улучшать точность рекомендаций и прогнозов.
Методы машинного обучения имитируют человеческое обучение. Представьте ребенка, который учится читать. Процесс обучения начинается не с зазубривания всех правил грамматики и орфографии: сначала ребенок читает простые, детские книги, затем переходит к более сложной литературе, из которой он получает новые знания и усваивает новые правила. По похожему принципу работает машинное обучение.
С развитием алгоритмов стало понятно, что некоторые задачи, например, распознавание речи или текста, компьютер решить всё ещё не может. В результате возникла идея нейронных сетей, которые имитируют не просто процесс обучения человека, но само устройство человеческого мозга.
Искусственные нейронные сети представляют из себя систему связанных между собой простых процессоров (искусственных нейронов), обменивающихся друг с другом сигналами (нервными импульсами). Нейронная сеть имитирует центральную нервную систему и может решать более сложные задачи машинного обучения — прогнозирование временных рядов, распознавание речи, компьютерное зрение и другие.
Машинное обучение можно разделить на четыре группы:
1. Контролируемое машинное обучение, или обучение с учителем (supervised machine learning) — для обучения алгоритмов используются labeled data (размеченные, или маркированные, данные). В контролируемом машинном обучении входные данные (X) и выходные данные (Y) известны. На предоставленном датасете из данных X и Y алгоритм обучается, чтобы затем предсказать значение Y на новом массиве данных.

2. Неконтролируемое машинное обучение, или обучение без учителя (unsupervised machine learning) — алгоритмы обучаются на unlabeled data (немаркированные, или неразмеченные, данные). В этом случае алгоритм получает только сырые входные данные, которые не требуют первичной обработки. Алгоритм анализирует датасет и самостоятельно проводит кластеризацию данных, разделяя их на группы со схожими показателями.

3. Обучение с подкреплением (reinforcement learning) — алгоритм обучается самостоятельно (на сырых данных), взаимодействуя с незнакомой средой и получая фидбек на свои действия. Основная задача алгоритма — методом проб и ошибок выбрать те тактики, которые позволят максимизировать общую выгоду агента.
Популярная тестовая среда для обучения с подкреплением — компьютерные игры, работающие по такому же принципу. Например, в арканоидах игрок получает очки, когда разбивает блоки, и теряет жизни, если дает шарику упасть. В процессе обучения с подкреплением алгоритм машинного обучения научится всегда отбивать шарик и даже сможет выбрать оптимальную стратегию, которая позволит быстрее всего выбить все блоки.

4. Частичное обучение, или обучение с частичным привлечением учителя (semi-supervised learning) — алгоритмы обучаются одновременно на labeled и unlabeled data, причём количество неразмеченных данных обычно сильно превышает количество маркированных. У этого метода есть несколько преимуществ. Во-первых, маркировка огромного массива данных — долгий и дорогостоящий процесс. Во-вторых, маркировка всех данных в массиве может привести к появлению в модели систематической ошибки, вызванной человеческим фактором. Включение в модель unlabeled data одновременно снижает стоимость обучения алгоритма и позволяет сделать модель более точной.
Что такое глубокое, или глубинное, обучение (Deep learning)
Deep learning — набор методов машинного обучения, в которых используются нейронные сети с большим количеством нейронов и слоев для извлечения признаков. В многослойной нейронной сети помимо входного (принимающего данные) и выходного (выдающего результат) слоев есть один или несколько скрытых слоев вычислительных нейронов для обработки данных. При этом каждый последующий слой получает на входе выходные данные предыдущего.
С помощью глубокого обучения можно анализировать огромные массивы данных, прикладывая меньше человеческих усилий для их первичной обработки. Deep learning позволяет получать более точные результаты, чем другие методы машинного обучения.
Принцип глубокого обучения хорошо описан в блоге Oracle на живом примере. «Когда вам показывают изображение лошади, вы понимаете, что это лошадь, даже если никогда раньше не видели именно эту картинку. Не имеет значения, лежит ли лошадь на диване или одета как бегемот. Вы узнаете ее, потому что помните множество определяющих ее признаков: форму головы, количество и расположение ног и другие. Глубокое обучение тоже умеет распознавать эти признаки.»
Это особенно важно для таких технологий, как беспилотные автомобили, которым необходимо «знать», что именно их окружает — люди, машины, велосипеды, дорожные знаки, бордюры и другие элементы. Традиционные методы машинного обучения не могут решить все задачи, необходимые для реализации этой технологии.

Глубокое обучение используют для решения задач, связанных с распознаванием лиц, речи, текста, фото и видео. Несколько примеров таких задач:
Глубинное обучение: возможности, перспективы и немного истории
Последние несколько лет словосочетание «глубинное обучение» всплывает в СМИ слишком часто. Различные журналы вроде KDnuggets и DigitalTrends стараются не упустить новости из этой сферы и рассказать о популярных фреймворках и библиотеках.
Даже популярные издания вроде The NY Times и Forbes стремятся регулярно писать о том, чем заняты ученые и разработчики из области deep learning. И интерес к глубинному обучению до сих пор не угасает. Сегодня мы расскажем о том, на что способно глубинное обучение сейчас, и по какому сценарию оно будет развиваться в будущем.

Пара слов про глубинное обучение, нейронные сети и ИИ
Чем отличается алгоритм глубинного обучения от обычной нейронной сети? По словам Патрика Холла, ведущего исследователя данных в компании SAS, самое очевидное отличие: в нейронной сети, используемой в глубинном обучении, больше скрытых слоев. Эти слои находятся между первым, или входным, и последним, выходным, слоем нейронов. При этом совсем не обязательно связывать все нейроны на разных уровнях между собой.
Разграничение глубинного обучения и искусственного интеллекта не такое однозначное. Например, профессор Вашингтонского университета Педро Домингос соглашается с мнением, что глубинное обучение выступает гипонимом по отношению к термину «машинное обучение», которое в свою очередь является гипонимом по отношению к искусственному интеллекту. Домингос говорит, что на практике области их применения пересекаются достаточно редко.
Однако существует и другое мнение. Хуго Ларочелле, профессор Шербрукского университета, уверен, что данные концепты почти никак не связаны между собой. Хуго замечает, что ИИ фокусируется на цели, а глубинное обучение — на определенной технологии или методологии, необходимой для машинного обучения. Поэтому здесь и далее, говоря о достижениях в области ИИ (таких, как AlphaGo, например) будем иметь в виду, что подобные разработки используют алгоритмы глубинного обучения — но наряду и с другими разработками из области ИИ в целом и машинного обучения в частности [как справедливо отмечает Педро Домингос].
От «глубокой нейронной сети» до глубинного обучения
Глубокие нейронные сети появились достаточно давно, еще в 1980-е. Так почему же глубинное обучение начало активно развиваться только в 21 веке? Репрезентации в нейронной сети создаются в слоях, поэтому было логично предположить, что больше слоев позволит сети лучше обучаться. Но большую роль играет метод обучения сети. Раньше для глубинного обучения использовались те же алгоритмы, что и для обучения искусственных нейронных сетей — метод обратного шифрования. Такой метод мог эффективно обучать только последние слои сети, в результате чего процесс был чрезвычайно длительным, а скрытые слои глубинной нейронной сети, фактически, не «работали».
Только в 2006 году три независимых группы ученых смогли разработать способы преодоления трудностей. Джеффри Хинтон смог провести предобучение сети при помощи машины Больцмана, обучая каждый слой отдельно. Для решения проблем распознавания изображений Яном ЛеКаном было предложено использование сверточной нейронной сети, состоящей из сверточных слоев и слоев подвыборки. Каскадный автокодировщик, разработанный Иошуа Бенджио, также позволил задействовать все слои в глубокой нейронной сети.
Проекты, которые «видят» и «слышат»
Сегодня глубинное обучение используется в совершенно разных сферах, но, пожалуй больше всего примеров использования лежит в области обработки изображений. Функция распознавания лиц существует уже давно, но, как говорится, нет предела совершенству. Разработчики сервиса OpenFace уверены, что проблема еще не решена, ведь точность распознавания можно повысить. И это не просто слова, OpenFace умеет различать даже похожих внешне людей. Подробно о работе программы уже писали в этой статье. Глубинное обучение поможет и при работе с черно-белыми файлами, автоматической колоризацией которых занимается приложение Colornet.
Кроме того, глубокие сети теперь способны распознавать и человеческие эмоции. А вместе с возможностью отследить использование логотипа компании на фотографиях и анализом сопроводительного текста мы получаем мощный маркетинговый инструмент. Похожие сервисы разрабатывает, например, IBM. Инструмент позволяет оценить авторов текстов при поиске блогеров для сотрудничества и рекламы.
Программа NeuralTalk умеет описывать изображения при помощи нескольких предложений. В базу программы загружается набор изображений и 5 предложений, описывающих каждое из них. На стадии обучения алгоритм учится прогнозировать предложения на основе ключевого слова, используя предыдущий контекст. А на стадии прогнозирования нейронная сеть Джордана уже создает предложения, описывающие картинки.
Сегодня существует много приложений, которые могут решать разные задачи в работе с аудио. Например, приложение Magenta, разработанное командой Google, умеет создавать музыку. Но большая часть приложений направлена на распознавание речи. Интернет-сервис Google Voice умеет транскрибировать голосовую почту и имеет функции управления СМС, при этом для обучения глубоких сетей исследователями использовались существующие голосовые сообщения.
Проекты в «разговорном жанре»
По мнению таких ученых, как Ноам Хомски, невозможно научить компьютер полностью понимать речь и вести осознанный диалог, потому что даже механизм человеческой речи изучен не до конца. Попытки научить машины говорить начались еще в 1968 году, когда Терри Виноград создал программу SHRDLU. Она умела распознавать части речи, описывать предметы, отвечать на вопросы, даже обладала небольшой памятью. Но попытки расширить словарный запас машины привели к тому, что стало невозможно контролировать применение правил.
Но сегодня с помощью глубинного обучения Google в лице разработчика Куока Ле шагнул далеко вперед. Его разработки умеют отвечать на письма в Gmail и даже помогают специалистам технической поддержки Google. А программа Cleverbot обучалась на диалогах из 18 900 фильмов. Поэтому она может отвечать на вопросы даже о смысле жизни. Так, бот считает, что смысл жизни заключается в служении добру. Однако ученые вновь столкнулись с тем, что искусственный интеллект лишь имитирует понимание и не имеет представления о реальности. Программа воспринимает речь лишь как сочетание определенных символов.
Обучение машин языку может помочь и в переводе. Google давно занимается улучшением качества перевода в своем сервисе. Но насколько можно приблизить машинный перевод к идеалу, если и человек не всегда может правильно понимать смысл высказывания? Рэй Курцвейл предлагает для решения этой задачи графически представить семантическое значение слов в языке. Процесс достаточно трудоемкий: в специальный каталог Knowledge Graph, созданный в Google, ученые загрузили данные о почти 700 миллионах тем, мест, людей, между которыми было проведено почти миллиард различных связей. Все это направлено на улучшение качества перевода и восприятие искусственным интеллектом языка.
Сама идея о представлении языка графическими и/или математическими методами не нова. Еще в 80-е перед учеными стояла задача представить язык в формате, с которым могла бы работать нейронная сеть. В итоге был предложен вариант представления слов в виде математических векторов, что позволяло точно определить смысловую близость разных слов (например, в векторном пространстве слова «лодка» и «вода» должны быть близки друг к другу). На этих исследованиях и базируются сегодняшние разработки Google, которые современные исследователи называют уже не «векторами отдельных слов», а «векторами идей».
Глубинное обучение и здравоохранение
Сегодня глубинное обучение проникает даже в сферу здравоохранения и помогает следить за состоянием пациентов не хуже врачей. Например, медицинский центр Дармут-Хичкок в США использует специализированный сервис Microsoft ImagineCare, что позволяет врачам уловить едва заметные перемены в состоянии пациентов. Алгоритмы получают данные об изменениях веса, контролируют давление пациентов и могут даже распознавать эмоциональное состояние на основе анализа телефонных разговоров.
Глубинное обучение применяется и в фармацевтике. Сегодня для лечения разных видов рака используется молекулярно-таргетная терапия. Но для создания эффективного и безопасного лекарства необходимо идентифицировать активные молекулы, которые бы воздействовали только на заданную мишень, позволяя избежать побочных эффектов. Поиск таких молекул может выполняться с использованием глубинного обучения (описание проекта, проведенного совместно учеными из университетов Австрии, Бельгии и R&D-отдела компании Johnson&Johnson есть в этом научном материале).
Есть ли у алгоритма интуиция?
Насколько на самом деле «глубоко» глубинное обучение? Ответ на это вопрос могут дать разработчики AlphaGo. Этот алгоритм не умеет говорить, не умеет распознавать эмоции. Но он способен обыграть любого в настольную игру. На первый взгляд тут нет ничего особенного. Уже почти 20 лет назад компьютер, разработанный IBM, впервые обыграл в шахматы человека. Но AlphaGo – совсем другое дело. Настольная игра Го появилась в Древнем Китае. Начало чем-то похоже на шахматы – противники играют на доске в клетку, черные фигуры против белых. Но на этом сходства заканчиваются, потому что фигуры являются небольшими камушками, а цель игры – окружить камушек противника своими.
Но главное отличие в том, что не существует каких-либо заранее известных выигрышных комбинаций, в го невозможно думать на несколько ходов вперед. Машину нельзя запрограммировать на победу, потому что невозможно выстроить победную стратегию заранее. Здесь и вступает в игру глубинное обучение. Вместо программирования определенных ходов, AlphaGo проанализировала сотни тысяч сыгранных партий и сыграла миллион партий сама с собой. Искусственный интеллект может обучаться на практике и выполнять сложные задания, приобретая то, что человек назвал бы «интуитивным пониманием выигрышной стратегии».
Машины не захватят мир
Несмотря на ошеломляющие успехи AlphaGo, искусственный интеллект еще далек от порабощения человеческой расы. Машины научились своеобразному «интуитивному мышлению», обработке огромного массива данных, но, по словам Фей-Фей Ли, руководителя Стэнфордской лаборатории искусственного интеллекта, абстрактное и творческое мышление им недоступно.
Несмотря на определенный прогресс в распознавании изображений, компьютер может перепутать дорожный знак с холодильником. Вместе со своими коллегами Ли составляет базу изображений с их подробным описанием и большим количеством тегов, которые позволят компьютеру получить больше информации о реальных объектах.
По словам Ли, такой подход – обучение на основе фото и подробного его описания – похож на то, как учатся дети, ассоциируя слова с объектами, отношениями и действиями. Конечно, эта аналогия довольно грубая – ребенку для понимания взаимосвязей объектов реального мира не нужно дотошно описывать каждый предмет и его окружение.
Профессор Джош Тененбаум, изучающий когнитивистику в MIT, отмечает, что, алгоритм познания мира и обучения у компьютера сильно отличается от процесса познания у человека; несмотря на свой размер, искусственные нейронные сети не могут сравниться с устройством биологических сетей. Так, способность говорить формируется в человеке очень рано и базируется на визуальном восприятии мира, владении опорно-двигательным аппаратом. Тененбаум уверен, что научить машины полноценному мышлению без подражания человеческой речи и психологической составляющей не представляется возможным.
Фей-Фей Ли согласна с этим мнением. По словам ученой, современный уровень работы с искусственным интеллектом не позволит приблизить его к человеческому – как минимум за счет наличия у людей эмоционального и социального интеллекта. Поэтому захват мира машинами стоит отложить как минимум еще на пару десятилетий.