nlp машинное обучение что это
Обработка естественного языка
Содержание
Задачи [ править ]
| Определение: |
| Корпус — подобранная и обработанная по определённым правилам совокупность текстов, используемых в качестве базы для исследования языка. |
NLP решает большой набор задач, который можно разбить по уровням (в скобках). Среди этих задач, можно выделить следующие:
Основные подходы [ править ]
Предобработка текста [ править ]
Предобработка текста переводит текст на естественном языке в формат удобный для дальнейшей работы. Предобработка состоит из различных этапов, которые могут отличаться в зависимости от задачи и реализации. Далее приведен один из возможных набор этапов:
Стемминг [ править ]
Количество корректных словоформ, значения которых схожи, но написания отличаются суффиксами, приставками, окончаниями и прочим, очень велико, что усложняет создание словарей и дальнейшую обработку. Стемминг позволяет привести слово к его основной форме. Суть подхода в нахождении основы слова, для этого с конца и начала слова последовательно отрезаются его части. Правила отсекания для стеммера создаются заранее, и чаще всего представляют из себя регулярные выражения, что делает данный подход трудоемким, так как при подключении очередного языка нужны новые лингвистические исследования. Вторым недостатком подхода является возможная потеря информации при отрезании частей, например, мы можем потерять информацию о части речи.
Лемматизация [ править ]
Данный подход является альтернативой стемминга. Основная идея в приведении слова к словарной форме — лемме. Например для русского языка:
Векторизация [ править ]
Большинство математических моделей работают в векторных пространствах больших размерностей, поэтому необходимо отобразить текст в векторном пространстве. Основным походом является мешок слов (bag-of-words): для документа формируется вектор размерности словаря, для каждого слова выделяется своя размерность, для документа записывается признак насколько часто слово встречается в нем, получаем вектор. Наиболее распространенным методом для вычисления признака является TF-IDF [4] (TF — частота слова, term frequency, IDF — обратная частота документа, inverse document frequency). TF вычисляется, например, счетчиком вхождения слова. IDF обычно вычисляют как логарифм от числа документов в корпусе, разделённый на количество документов, где это слово представлено. Таким образом, если какое-то слово встретилось во всех документах корпуса, то такое слово не будет никуда добавлено. Плюсами мешка слов является простая реализация, однако данный метод теряет часть информации, например, порядок слов. Для уменьшения потери информации можно использовать мешок N-грамм (добавлять не только слова, но и словосочетания), или использовать методы векторных представлений слов это, например, позволяет снизить ошибку на словах с одинаковыми написаниями, но разными значениями.
Дедубликация [ править ]
Так как количество схожих документов в большом корпусе может быть велико, необходимо избавляться от дубликатов. Так как каждый документ может быть представлен как вектор, то мы можем определить их близость, взяв косинус или другую метрику. Минусом является то, что для больших корпусов полный перебор по всем документам будет невозможен. Для оптимизации можно использовать локально-чувствительный хеш, который поместит близко похожие объекты.
Семантический анализ [ править ]
Семантический (смысловой) анализ текста — выделение семантических отношений, формировании семантического представления. В общем случае семантическое представление является графом, семантической сетью, отражающим бинарные отношения между двумя узлами — смысловыми единицами текста. Глубина семантического анализа может быть разной, а в реальных системах чаще всего строится только лишь синтаксико-семантическое представление текста или отдельных предложений. Семантический анализ применяется в задачах анализа тональности текста [5] (Sentiment analysis), например, для автоматизированного определения положительности отзывов.
Распознавание именованных сущностей и извлечение отношений [ править ]
Именованные сущности — объекты из текста, которые могут быть отнесены к одной из заранее заявленных категорий (например, организации, личности, адреса). Идентификация ссылок на подобные сущности в тексте является задачей распознавания именованных сущностей.
Определение семантических отношений между именованными сущностями или другими объектами текста, является задачей извлечения отношений. Примеры отношений: (автор,книга), (организация,главный_офис).
Использование N-грамм [ править ]
В NLP N-граммы используются для построения вероятностных моделей, задач схожести текстов, категоризации текста и языка.
Построив N-граммную модель можно определить вероятность употребления заданной фразы в тексте. N-граммная модель рассчитывает вероятность последнего слова N-граммы, если известны все предыдущие, при этом полагается, что вероятность появления каждого слова зависит только от предыдущих слов.
Использование N-грамм применяется в задаче выявления плагиата. Текст разбивается на несколько фрагментов, представленных N-граммами. Сравнение N-грамм друг с другом позволяет определить степень сходства документов. Аналогичным способом можно решать задачу исправления орфографических ошибок, подбирая слова кандидаты для замены.
Частеречная разметка [ править ]
Частеречная разметка (POS-тэгирование, англ. part-of-speech tagging) используется в NLP для определения части речи и грамматических характеристик слов в тексте с приписыванием им соответствующих тегов. Модель необходима, когда значение слова зависит от контекста. Например, в предложениях «Столовая ложка» и «Школьная столовая» слово «столовая» имеет разные части речи. POS-тэгирование позволяет сопоставить слову в тексте специальный тэг на основе его значения и контекста.
Алгоритмы частеречной разметки делятся на несколько групп:
POS-тэгирование является неотъемлемой частью обработки естественного языка. Без частеречной разметки становится невозможным дальнейший анализ текста из-за возникновения неопределенностей в значениях слов. Данный алгоритм используется при решении таких задач как перевод на другой язык, определение смысла текста, проверка на пунктуационные и речевые ошибки. Также можно автоматизировать процесс определения хештегов у постов и статей, выделяя существительные в приведенном тексте.
Библиотеки для NLP [ править ]
NLTK (Natural Language ToolKit) [14] [ править ]
Пакет библиотек и программ для символьной и статистической обработки естественного языка, написанных на Python и разработанных по методологии SCRUM. Содержит графические представления и примеры данных. Поддерживает работу с множеством языков, в том числе, русским.
spaCy [15] [ править ]
Библиотека, разработанная по методологии SCRUM на языке Cypthon, позиционируется как самая быстрая NLP библиотека. Имеет множество возможностей, в том числе, разбор зависимостей на основе меток, распознавание именованных сущностей, пометка частей речи, векторы расстановки слов. Не поддерживает русский язык.
scikit-learn [16] [ править ]
Библиотека scikit-learn разработана по методологии SCRUM и предоставляет реализацию целого ряда алгоритмов для обучения с учителем и обучения без учителя через интерфейс для Python. Построена поверх SciPy. Ориентирована в первую очередь на моделирование данных, имеет достаточно функций, чтобы использоваться для NLP в связке с другими библиотеками.
gensim [17] [ править ]
Python библиотека, разработанная по методологии SCRUM, для моделирования, тематического моделирования документов и извлечения подобия для больших корпусов. В gensim реализованы популярные NLP алгоритмы, например, word2vec. Большинство реализаций могут использовать несколько ядер.
Балто-славянские языки имеют сложную морфологию, что может ухудшить качество обработки текста, а также ограничить использование ряда библиотек. Для работы со специфичной русской морфологией можно использовать, например, морфологический анализатор pymorphy2 [18] и библиотеку для поиска и извлечения именованных сущностей Natasha [19]
Правильный NLP: как работают и что умеют системы обработки естественного языка
Авторизуйтесь
Правильный NLP: как работают и что умеют системы обработки естественного языка

руководитель практики новых технологий компании Accenture в России
Основные факторы роста рынка NLP: стали больше использоваться интеллектуальные устройства, а также облачные решения и приложения на основе NLP, которые улучшают обслуживание клиентов, увеличились технологические инвестиции в отрасль здравоохранения.
Какие задачи сегодня может решать NLP?
Машинный перевод текстов с одного языка на другой

Это один из самых распространённых сценариев. Однако несмотря на значительный прогресс машинного перевода, современные решения до сих пор не всегда справляются с переводом устойчивых оборотов, игры слов, а также выбором подходящих падежей и правильным построением предложений.
Анализ текстов
Анализ текстов реализуется в трёх основных форматах: классификации, отражении содержания и анализе тональности.
Все задачи по классификации текстов (text classification) можно разделить на два типа:
Отражение содержания текста (text summarization) работает так: на вход NLP-система принимает текст большого размера, а на выходе отдаёт текст меньшего размера, отражающий содержание большого.
Например, от машины можно потребовать сгенерировать пересказ текста, заголовок или аннотацию. Чуть подробнее про генерацию текста можно почитать в материале «Генерируем заголовки фейковых новостей в стиле Ленты.ру» с подробным разбором способов, которыми можно обучить нейросети созданию осмысленных и забавных для человеческого восприятия заголовков.

Наконец, анализ тональности текста (sentiment analysis) позволяет находить в тексте мнения и выявлять их свойства. Какие именно свойства будут исследоваться, зависит от поставленной задачи. К примеру, целью анализа может быть сам автор — анализ тональности определяет типичный для него стиль, эмоциональную окраску текста и т. д.
Распознавание и синтез речи
Распознавание речи представляет собой процесс преобразования речевого сигнала в цифровую информацию, например в текст. Синтез речи работает в обратном направлении, формируя речевой сигнал по печатному тексту.
Синтез и распознавание речи применяются в самых разных областях, например, в работе голосовых ассистентов, IVR-систем и «умных домах».
Разработка диалоговых систем
Диалоговыми системами можно считать:
Все они опираются на NLP-инструменты: распознавание речи, выделение смысла, контекста, определение намерения, а затем выстраивание диалога, исходя из вышеперечисленного (в идеале — путём синтеза речи).
Выделение сущностей и фактов
Ещё одна популярная задача NLP — извлечение именованных сущностей (Named-entity recognition, NER) из текста. Представим, что у есть сплошной текст о покупке-продаже активов, и необходимо выделить персон, а также даты и активы.
На фоне роста аналитических прогнозов, миллиардер Иван Петров выкупил контрольный пакет акций компании « Рога и Копыта » в 1999 году.
Задача NER — понять, что участок текста «1999 года» является датой, «Иван Петров» — персоной, а «пакет акций» — активом.
Без NER тяжело представить решение многих задач NLP, допустим, разрешения местоименной анафоры или построения вопросно-ответных систем. Если задать в поисковике вопрос «Кто играл роль Бэтмена в фильме “Темный рыцарь”», то ответ находится как раз с помощью выделения именованных сущностей: выделяем сущности (фильм, роль и т. п.), понимаем, что спрашивается, и дальше ищем ответ в базе данных.
Постановка задачи NER очень гибкая. Можно выделять любые нужные непрерывные фрагменты текста, которые чем-то отличаются от остального текста. В результате можно подобрать свой набор сущностей для конкретной практической задачи, обработать тексты этим набором и обучить модель. Такой сценарий встречается повсеместно, и это делает NER одной из самых часто решаемых задач NLP в индустрии.
Вот как выглядит подобный проект для крупной нефтяной компании. Перед заказчиком стояла задача подготовить данные об активах: промышленных установках, эксплуатируемом оборудовании, а также средствах измерения и контроля. Источниками данных служили текстовые документы — технические регламенты, наиболее полно описывающие техпроцессы и необходимые объекты производства.

Мы продемонстрировали возможность применения технологий ML и NLP для извлечения информации из текстового описания (и формирования профилей оборудования на её основе). Сформированные профили были сопоставлены с результатами ручного маппинга, взятого за эталон — достигнутая точность составила 97,3%. Подход позволяет существенно снизить затраты труда и времени, а также свести к минимуму риски, связанные с ошибками ручной обработки текстов.
Как обрабатывается естественный язык?
Некоторые задачи NLP для естественного языка, в отличие от обработки изображений, до недавних пор решались с помощью классических алгоритмов машинного обучения.
Для решения большинства задач требовался тщательный выбор архитектуры, а также ручной сбор и обработка признаков. Однако в последнее время нейронные сети начали давать более точные результаты по сравнению с классическими моделями и сформировали общий подход для решения задач NLP.
Конвейер NLP
Реализация любой сложной задачи обычно означает построение пайплайна (конвейера).

Суть этого подхода в том, чтобы разбить задачу на ряд последовательных подзадач и решать каждую из них отдельно. В построении пайплайна можно условно выделить две части: предобработку входных данных (обычно занимает больше всего времени) и построение модели. Основных этапов — семь.
1. Первые два шага пайплайна, которые выполняются для решения практически любых задач NLP, — это сегментация (деление текста на предложения) и токенизация (деление предложений на токены, то есть отдельные слова).
2. Вычисление признаков каждого токена. Вычисляются контекстно-независимые признаки токена. Это набор признаков, не зависящих от соседних с токеном слов.

Например: I had a pony. I had two ponies.
Оба предложения содержат существительное «pony», но с разными окончаниями. Если тексты обрабатывает компьютер, он должен знать начальную форму каждого слова, чтобы понимать, что речь идёт об одной и той же концепции пони. Иначе токены «pony» и «ponies» будут восприняты как совершенно разные. В NLP этот процесс называется лемматизацией.
3. Определение значимости и фильтрация стоп-слов. В русском и английском языках очень много вспомогательных слов, например «and», «the», «a». При статистическом анализе текста эти токены создают много шума, так как появляются чаще, чем остальные. Поэтому их отмечают как стоп-слова и отсеивают.

4. Разрешение кореференции. В русском и английском языках очень много местоимений вроде he, she, it или ты, я, он и т. д. Это сокращения, которыми мы заменяем на письме настоящие имена и названия. Человек может проследить взаимосвязь этих слов от предложения к предложению, основываясь на контексте. Но NLP-модель не знает, что означают местоимения, ведь она рассматривает всего одно предложение за раз.

5. Парсинг зависимостей. Конечная цель этого шага — построение дерева, в котором каждый токен имеет единственного родителя. Корнем может быть главный глагол. Также нужно установить тип связи между двумя словами:

Это дерево парсинга демонстрирует, что главный субъект предложения — это существительное «London». Между ним и «capital» есть связь «be». Вот так мы узнали, что Лондон — это столица. Если бы мы проследовали дальше по веткам дерева (уже за границами схемы), то могли бы узнать, что «London is the capital of Great Britain».
6. Перевод обработанного текста в векторную форму. Данный шаг позволяет сформировать векторные представления слов. Таким образом, у слов, используемых в одном и том же контексте, похожие векторы.
7. Построение модели в зависимости от поставленной цели. Например, модель для классификации или генерации новых текстов.
Приведённый пример пайплайна не является единственно верным. Для решения конкретной задачи некоторые шаги можно исключить или добавить новые. Однако этот пайплайн содержит все наиболее типичные этапы и подходы, позволяющие извлекать практическую пользу из NLP.
Плавное введение в Natural Language Processing (NLP)
Введение в NLP с Sentiment Analysis в текстовых данных.
Люди общаются с помощью каких-либо форм языка и пользуются либо текстом, либо речью. Сейчас для взаимодействия компьютеров с людьми, компьютерам необходимо понимать естественный язык, на котором говорят люди. Natural language processing занимается как раз тем, чтобы научить компьютеры понимать, обрабатывать и пользоваться естественными языками.
В этой статье мы рассмотрим некоторые частые методики, применяющиеся в задачах NLP. И создадим простую модель сентимент-анализа на примере обзоров на фильмы, чтобы предсказать положительную или отрицательную оценку.
Что такое Natural Language Processing (NLP)?
NLP — одно из направлений искуственного интеллекта, которое работает с анализом, пониманем и генерацией живых языков, для того, чтобы взаимодействовать с компьютерами и устно, и письменно, используя естественные языки вместо компьютерных.
Применение NLP
Очистка данных (Data Cleaning):
При Data Cleaning мы удаляем из исходных данных особые знаки, символы, пунктуацию, тэги html <> и т.п., которые не содержат никакой полезной для модели информации и только добавляют шум в данные.
 Код на Python: Data cleaning
Код на Python: Data cleaning
Предварительная обработка данных (Preprocessing of Data)
Preprocessing of Data это этап Data Mining, который включает в себя трансформацию исходных данных в доступный для понимания формат.
Изменение регистра:
Одна из простейших форм предварительной обработки текста — перевод всех символов текста в нижний регистр.
 Источник изображения
Источник изображения
 Код на Python: перевод в нижний регистр
Код на Python: перевод в нижний регистр
Токенизация:
Токенизация — процесс разбиения текстового документа на отдельные слова, которые называются токенами.
 Код на Python: Токенизация
Код на Python: Токенизация
Как можно видеть выше, предложение разбито на слова (токены).
Natural language toolkit (библиотека NLTK) — популярный открытый пакет библиотек, используемых для разного рода задач NLP. В этой статье мы будем использовать библиотеку NLTK для всех этапов Text Preprocessing.
Вы можете скачать библиотеку NLTK с помощью pip:
Удаление стоп-слов:
Стоп-слова — это часто используемые слова, которые не вносят никакой дополнительной информации в текст. Слова типа «the», «is», «a» не несут никакой ценности и только добавляют шум в данные.
В билиотеке NLTK есть встроенный список стоп-слов, который можно использовать, чтобы удалить стоп-слова из текста. Однако это не универсальный список стоп-слов для любой задачи, мы также можем создать свой собствпнный набор стоп-слов в зависимости от сферы.
 Код на Python: Удаление стоп-слов
Код на Python: Удаление стоп-слов
В библиотеке NLTK есть заранее заданный список стоп-слов. Мы можем добавитьили удалить стоп-слова из этого списка или использовать его в зависимости от конкретной задачи.
Стеммизация:
Стеммизация — процесс приведения слова к его корню/основе.
Он приводит различные вариации слова (например, «help», «helping», «helped», «helpful») к его начальной форме (например, «help»), удаляет все придатки слов (приставка, суффикс, окончание) и оставляет только основу слова.
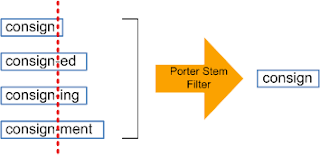 Источник изображения
Источник изображения
 Код на Python: Стеммизация
Код на Python: Стеммизация
Корень слова может быть существующим в языке словом, а может и не быть им. Например, «mov» корень слова «movie», «emot» корень слова «emotion».
Лемматизация:
Лемматизация похожа на стеммизацию в том, что она приводит слово к его начальной форме, но с одним отличием: в данном случае корень слова будет существующим в языке словом. Например, слово «caring» прекратится в «care», а не «car», как в стеммизаци.
 Код на Python: Лемматизация
Код на Python: Лемматизация
WordNet — это база существующих в английском языке слов. Лемматизатор из NLTK WordNetLemmatizer() использует слова из WordNet.
N-граммы:
 Источник изображения
Источник изображения
N-граммы — это комбинации из нескольких слов, использующихся вместе, N-граммы, где N=1 называются униграммами (unigrams). Подобным же образом, биграммы (N=2), триграммы (N=3) и дальше можно продолдать аналогичным способом.
N-граммы могут использоваться, когда нам нужно сохранить какую-то последовательность данных, например, какое слово чаще следует за заданным словом. Униграммы не содержат никкой последовательности данных, так как каждое слово берется индивидуально.
Векторизация текстовых данных (Text Data Vectorization):
Процесс конвертации текста в числа называется векторизацией. Теперь после Text Preprocessing, нам нужно представить текст в числовом виде, то есть закодировать текстовые данные в виде чисел, которые в дальнейшем могут использоваться в алгоритмах.
«Мешок слов» (Bag of words (BOW)):
Это одна из самых простых методик векторизации текста. В логике BOW два предложения могут называться одинаковыми, если содержат один и тот же набор слов.
Рассмотрим два предложения:
 Источник изображения
Источник изображения
В задачах NLP, каждое текстовое предложение называется документом, а несколько таких документов называют корпусом текстов.
BOW создает словарь уникальных d слов в корпусе (собрание всех токенов в данных). Например, корпус на изображении выше состоит из всех слов предложений S1 и S2.
Теперь мы можем создать таблицу, где столбцы соответствуют входящим в корпус уникальным d словам, а строки предложениям (документам). Мы устанавливаем значение 1, если слово в предложении есть, и 0, если его там нет.
 Источник изображения
Источник изображения
Это позволит создать dxn матрицу, где d это общее число уникальных токенов в корпусе и n равно числу документов. В примере выше матрица будет иметь форму 11×2.
TF-IDF:
 Источник изображения
Источник изображения
Это расшифровывается как Term Frequency (TF)-Inverse Document Frequency (IDF).
Частота слова (Term Frequency):
Term Frequency высчитывает вероятность найти какое-то слово в документе. Ну, например, мы хотим узнать, какова вероятрность найти слово wi в документе dj.
Term Frequency (wi, dj) =
Количество раз, которое wi встречается в dj / Общее число слов в dj
Обратная частота документа (Inverse Document Frequency):
В логике IDF, если слово встречается во всех документах, оно не очень полезно. Так определяется, насколько уникально слово во всем корпусе.
Здесь Dc = Все документы в корпусе,
N = Общее число документов,
ni = документы, которые содержат слово (wi).
Если wi встречается в корпусе часто, значение IDF снижается.
Если wi используется не часто, то ni снижается и вследствие этого значение IDF возрастает.
TF-IDF — умножение значений TF и IDF. Больший вес получат слова, которые встречаются в документе чаще, чем во всем остальном корпусе.
Sentiment Analysis: Обзоры фильмов на IMDb
 Источник изображения
Источник изображения
Краткая информация
Набор данных содержит коллекцию из 50 000 рецензий на сайте IMDb, с равным количеством положительных и отрицательных рецензий. Задача — предсказать полярность (положительную или отрицательную) данных отзывов (тексты).
1. Загрузка и исследование данных
Набор данных IMDB можно скачать здесь.
Обзор набора данных:
 Положительные рецензии отмечены 1, а отрицательные 0.
Положительные рецензии отмечены 1, а отрицательные 0.
Пример положительной рецензии:

Пример отрицательной рецензии:

2. Data Preprocessing
 На этом этапе мы совершаем все шаги очистки и предварительной обработки данных тем методом, который был описан выше. Мы используем лемматизацию, а не стеммизацию, потому что в процессе тестирования результатов обоих случаев лемматизация дает лучшие результаты, чем стеммизация.
На этом этапе мы совершаем все шаги очистки и предварительной обработки данных тем методом, который был описан выше. Мы используем лемматизацию, а не стеммизацию, потому что в процессе тестирования результатов обоих случаев лемматизация дает лучшие результаты, чем стеммизация.
Использовать ли стеммизацию или лемматизацию или и то, и другое — зависит от поставленной задачи, так что нам стоит попробовать и решить, какой способ сработает лучше для данной задачи.

Добавляем новую колонку preprocessed_review в dataframe, применяя data_preprocessing() ко всем рецензиям.
3. Vectorizing Text (рецензии)
Разделяем набор данных на train и test (70–30):

Используем train_test_split из sklearn, чтобы разделить данные на train и test. Здесь используем параметр stratify,чтобы иметь равную пропорцию классов в train и test.
BOW

Здесь мы использовали min_df=10, так как нам нужны были только те слова, которые появляются как минимум 10 раз во всем корпусе.
TF-IDF

4. Создание классификаторов ML
Наивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными BOW

Naive Bayes c BOW выдает точность 84.6%. Попробуем с TF-IDF.
Наивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными TF-IDF

TF-IDF выдает результат немного лучше (85.3%), чем BOW. Теперь давайте попробуем TF-IDF с простой линеарной моделью, Logistic Regression.
Logistic Regression с рецензиями, закодированными TF-IDF

Logistic Regression с рецензиями, закодированными TF-IDF, выдает результат лучше, чем наивный байемовский — точность 88.0%.
 Построение матрицы неточностей даст нам информацию о том, сколько точек данных верны и сколько неверны, классифицированную с помощью модели.
Построение матрицы неточностей даст нам информацию о том, сколько точек данных верны и сколько неверны, классифицированную с помощью модели.
Из 7500 отрицательных рецензий 6515 были верно классифицированы как отрицательные и 985 были неверно классифицированы как положительные. Из 7500 положительных рацензий 6696 были верно классифицированы как положительные, и 804 неверно классифицированы как отрицательные.
Итоги
Мы узнали основные задачи NLP и создали простые модели ML для сентимент-анализа рецензий на фильмы. В дальнейшем усоверешенствований можно добиться с помощью Word Embedding с моделями Deep Learning.
Благодарю за внимание! Полный код смотрите здесь.