Увеличить память java машины
Управление памятью Java
Это глубокое погружение в управление памятью Java позволит расширить ваши знания о том, как работает куча, ссылочные типы и сборка мусора.
Вероятно, вы могли подумать, что если вы программируете на Java, то вам незачем знать о том, как работает память. В Java есть автоматическое управление памятью, красивый и тихий сборщик мусора, который работает в фоновом режиме для очистки неиспользуемых объектов и освобождения некоторой памяти.
Поэтому вам, как программисту на Java, не нужно беспокоиться о таких проблемах, как уничтожение объектов, поскольку они больше не используются. Однако, даже если в Java этот процесс выполняется автоматически, он ничего не гарантирует. Не зная, как устроен сборщик мусора и память Java, вы можете создать объекты, которые не подходят для сбора мусора, даже если вы их больше не используете.
Для начала давайте посмотрим, как обычно организована память в Java:
 Структура памяти
Структура памяти
Стек (Stack)
Стековая память отвечает за хранение ссылок на объекты кучи и за хранение типов значений (также известных в Java как примитивные типы), которые содержат само значение, а не ссылку на объект из кучи.
Кроме того, переменные в стеке имеют определенную видимость, также называемую областью видимости. Используются только объекты из активной области. Например, предполагая, что у нас нет никаких глобальных переменных (полей) области видимости, а только локальные переменные, если компилятор выполняет тело метода, он может получить доступ только к объектам из стека, которые находятся внутри тела метода. Он не может получить доступ к другим локальным переменным, так как они не выходят в область видимости. Когда метод завершается и возвращается, верхняя часть стека выталкивается, и активная область видимости изменяется.
Возможно, вы заметили, что на картинке выше отображено несколько стеков памяти. Это связано с тем, что стековая память в Java выделяется для каждого потока. Следовательно, каждый раз, когда поток создается и запускается, он имеет свою собственную стековую память и не может получить доступ к стековой памяти другого потока.
Куча (Heap)
Эта часть памяти хранит в памяти фактические объекты, на которые ссылаются переменные из стека. Например, давайте проанализируем, что происходит в следующей строке кода:
Ключевое слово new несет ответственность за обеспечение того, достаточно ли свободного места на куче, создавая объект типа StringBuilder в памяти и обращаясь к нему через «Builder» ссылки, которая попадает в стек.
Для каждого запущенного процесса JVM существует только одна область памяти в куче. Следовательно, это общая часть памяти независимо от того, сколько потоков выполняется. На самом деле структура кучи немного отличается от того, что показано на картинке выше. Сама куча разделена на несколько частей, что облегчает процесс сборки мусора.
Типы ссылок
Если вы внимательно посмотрите на изображение структуры памяти, вы, вероятно, заметите, что стрелки, представляющие ссылки на объекты из кучи, на самом деле относятся к разным типам. Это потому, что в языке программирования Java используются разные типы ссылок: сильные, слабые, мягкие и фантомные ссылки. Разница между типами ссылок заключается в том, что объекты в куче, на которые они ссылаются, имеют право на сборку мусора по различным критериям. Рассмотрим подробнее каждую из них.
1. Сильная ссылка
Это самые популярные ссылочные типы, к которым мы все привыкли. В приведенном выше примере со StringBuilder мы фактически храним сильную ссылку на объект из кучи. Объект в куче не удаляется сборщиком мусора, пока на него указывает сильная ссылка или если он явно доступен через цепочку сильных ссылок.
2. Слабая ссылка
Попросту говоря, слабая ссылка на объект из кучи, скорее всего, не сохранится после следующего процесса сборки мусора. Слабая ссылка создается следующим образом:
После сбора мусора ключа из WeakHashMap вся запись удаляется из карты.
3. Мягкая ссылка
Подобно слабым ссылкам, мягкая ссылка создается следующим образом:
4. Фантомная ссылка
Ссылки на String
Ссылки на тип String в Java обрабатываются немного по- другому. Строки неизменяемы, что означает, что каждый раз, когда вы делаете что-то со строкой, в куче фактически создается другой объект. Для строк Java управляет пулом строк в памяти. Это означает, что Java сохраняет и повторно использует строки, когда это возможно. В основном это верно для строковых литералов. Например:
При запуске этот код распечатывает следующее:
Следовательно, оказывается, что две ссылки типа String на одинаковые строковые литералы фактически указывают на одни и те же объекты в куче. Однако это не действует для вычисляемых строк. Предположим, что у нас есть следующее изменение в строке // 1 приведенного выше кода.
Strings are different
При добавлении вышеуказанного изменения создается следующий результат:
Процесс сборки мусора
Как обсуждалось ранее, в зависимости от типа ссылки, которую переменная из стека содержит на объект из кучи, в определенный момент времени этот объект становится подходящим для сборщика мусора.
 Объекты, подходящие для сборки мусора
Объекты, подходящие для сборки мусора
Например, все объекты, отмеченные красным цветом, могут быть собраны сборщиком мусора. Вы можете заметить, что в куче есть объект, который имеет строгие ссылки на другие объекты, которые также находятся в куче (например, это может быть список, который имеет ссылки на его элементы, или объект, имеющий два поля типа, на которые есть ссылки). Однако, поскольку ссылка из стека потеряна, к ней больше нельзя получить доступ, так что это тоже мусор.
Чтобы углубиться в детали, давайте сначала упомянем несколько вещей:
Этот процесс запускается автоматически Java, и Java решает, запускать или нет этот процесс.
На самом деле это дорогостоящий процесс. При запуске сборщика мусора все потоки в вашем приложении приостанавливаются (в зависимости от типа GC, который будет обсуждаться позже).
На самом деле это более сложный процесс, чем просто сбор мусора и освобождение памяти.
Несмотря на то, что Java решает, когда запускать сборщик мусора, вы можете явно вызвать System.gc() и ожидать, что сборщик мусора будет запускаться при выполнении этой строки кода, верно?
Это ошибочное предположение.
Вы только как бы просите Java запустить сборщик мусора, но, опять же, Java решать, делать это или нет. В любом случае явно вызывать System.gc() не рекомендуется.
Поскольку это довольно сложный процесс и может повлиять на вашу производительность, он реализован разумно. Для этого используется так называемый процесс «Mark and Sweep». Java анализирует переменные из стека и «отмечает» все объекты, которые необходимо поддерживать в рабочем состоянии. Затем все неиспользуемые объекты очищаются.
Так что на самом деле Java не собирает мусор. Фактически, чем больше мусора и чем меньше объектов помечены как живые, тем быстрее идет процесс. Чтобы сделать это еще более оптимизированным, память кучи на самом деле состоит из нескольких частей. Мы можем визуализировать использование памяти и другие полезные вещи с помощью JVisualVM, инструмента, поставляемого с Java JDK. Единственное, что вам нужно сделать, это установить плагин с именем Visual GC, который позволяет увидеть, как на самом деле структурирована память. Давайте немного увеличим масштаб и разберем общую картину:
 Поколения памяти кучи
Поколения памяти кучи
Когда объект создается, он размещается в пространстве Eden (1). Поскольку пространство Eden не такое уж большое, оно заполняется довольно быстро. Сборщик мусора работает в пространстве Eden и помечает объекты как живые.
Если объект выживает в процессе сборки мусора, он перемещается в так называемое пространство выжившего S0(2). Во второй раз, когда сборщик мусора запускается в пространстве Eden, он перемещает все уцелевшие объекты в пространство S1(3). Кроме того, все, что в настоящее время находится на S0(2), перемещается в пространство S1(3).
Если объект выживает в течение X раундов сборки мусора (X зависит от реализации JVM, в моем случае это 8), скорее всего, он выживет вечно и перемещается в пространство Old(4).
Принимая все сказанное выше, если вы посмотрите на график сборщика мусора (6), каждый раз, когда он запускается, вы можете увидеть, что объекты переключаются на пространство выживших и что пространство Эдема увеличивалось. И так далее. Старое поколение также может быть обработано сборщиком мусора, но, поскольку это большая часть памяти по сравнению с пространством Eden, это происходит не так часто. Метапространство (5) используется для хранения метаданных о ваших загруженных классах в JVM.
Представленное изображение на самом деле является приложением Java 8. До Java 8 структура памяти была немного другой. Метапространство на самом деле называется PermGen область. Например, в Java 6 это пространство также хранит память для пула строк. Поэтому, если в вашем приложении Java 6 слишком много строк, оно может аварийно завершить работу.
Типы сборщиков мусора
Фактически, JVM имеет три типа сборщиков мусора, и программист может выбрать, какой из них следует использовать. По умолчанию Java выбирает используемый тип сборщика мусора в зависимости от базового оборудования.
3. Mostly concurrent GC (В основном параллельный сборщик мусора). Если вы помните, ранее в этой статье упоминалось, что процесс сбора мусора на самом деле довольно дорогостоящий, и когда он выполняется, все потоки приостанавливаются. Однако у нас есть в основном параллельный тип GC, который утверждает, что он работает одновременно с приложением. Однако есть причина, по которой он «в основном» параллелен. Он не работает на 100% одновременно с приложением. Есть период времени, на который цепочки приостанавливаются. Тем не менее, пауза делается как можно короче для достижения наилучшей производительности сборщика мусора. На самом деле существует 2 типа в основном параллельных сборщиков мусора:
Примечание переводчика. Информация про сборщики мусора для различных версий Java приведена в переводе:
Советы и приемы
Чтобы минимизировать объем памяти, максимально ограничьте область видимости переменных. Помните, что каждый раз, когда выскакивает верхняя область видимости из стека, ссылки из этой области теряются, и это может сделать объекты пригодными для сбора мусора.
Явно устанавливайте в null устаревшие ссылки. Это сделает объекты, на которые ссылаются, подходящими для сбора мусора.
Избегайте финализаторов (finalizer). Они замедляют процесс и ничего не гарантируют. Фантомные ссылки предпочтительны для работы по очистке памяти.
JVisualVM также имеет функцию создания дампа кучи в определенный момент, чтобы вы могли анализировать для каждого класса, сколько памяти он занимает.
Настройте JVM в соответствии с требованиями вашего приложения. Явно укажите размер кучи для JVM при запуске приложения. Процесс выделения памяти также является дорогостоящим, поэтому выделите разумный начальный и максимальный объем памяти для кучи. Если вы знаете его, то не имеет смысла начинать с небольшого начального размера кучи с самого начала, JVM расширит это пространство памяти. Указание параметров памяти выполняется с помощью следующих параметров:
Если приложение Java выдает ошибку OutOfMemoryError и вам нужна дополнительная информация для обнаружения утечки, запустите процесс с –XX:HeapDumpOnOutOfMemory параметром, который создаст файл дампа кучи, когда эта ошибка произойдет в следующий раз.
Заключение
Как выделить Java больше оперативной памяти
Из-за взаимодействия программного компонента Java с разработанными продуктами могут возникать ошибки, решение которых лежит на плечах пользователя. Оно достигается двумя путями: переустановкой модуля и выделением дополнительной памяти Java. С каждой ситуацией стоит разобраться отдельно.
Зачем увеличивать память Java
Задачу по увеличению Java памяти пользователи ставят перед собой в следующих случаях:
Исправить проблему можно двумя способами.
Как выделить память Java
Выделить Джава-модулю больше оперативной памяти возможно через «Панель управления». Способ удобнее рассмотреть на примере проблем с запуском игры Minecraft.
Инструкция:
Если это не помогло запустить Minecraft, переустановите модуль Java и игру. После удаления очистите реестр с помощью CCleaner.
Увеличение памяти с помощью переменных среды
Чтобы система воспринимала написанные аргументы, нужно добавить переменную с названием «_JAVA_OPTIONS».
Если количество памяти, отведенной для работы Java, в два раза меньше имеющейся оперативки, то команды прописываются по следующей инструкции:
В примере объем оперативки составлял 1 Гб.
Видео: 3 способа выделить больше памяти Java.
Таким образом в статье рассмотрено два метода увеличения оперативной памяти, выделяемой для работы Java-модуля.
Развеиваем мифы об управлении памятью в JVM

Структура памяти JVM
Сначала давайте посмотрим на структуру памяти JVM. Эта структура применяется начиная с JDK 11. Вот какая память доступна процессу JVM, она выделяется операционной системой:

Это нативная память, выделяемая ОС, и её размер зависит от системы, процессор и JRE. Какие области и для чего предназначены?
Куча (heap)
Здесь JVM хранит объекты и динамические данные. Это самая крупная область памяти, в ней работает сборщик мусора. Размером кучи можно управлять с помощью флагов Xms (начальный размер) и Xmx (максимальный размер). Куча не передаётся виртуальной машине целиком, какая-то часть резервируется в качестве виртуального пространства, за счёт которого куча может в будущем расти. Куча делится на пространства «молодого» и «старого» поколения.
Стеки потоков исполнения
Метапространство
Кеш кода
Здесь компилятор Just In Time (JIT) хранит скомпилированные блоки кода, к которым приходится часто обращаться. Обычно JVM интерпретирует байткод в нативный машинный код, однако код, скомпилированный JIT-компилятором, не нужно интерпретировать, он уже представлен в нативном формате и закеширован в этой области памяти.
Общие библиотеки
Здесь хранится нативный код для любых общих библиотек. Эта область памяти загружается операционной системой лишь один раз для каждого процесса.
Использование памяти JVM: стек и куча
Теперь давайте посмотрим, как исполняемая программа использует самые важные части памяти. Воспользуемся нижеприведённым кодом. Он не оптимизирован с точки зрения корректности, так что игнорируйте проблемы вроде ненужных промежуточных переменных, некорректных модификаторов и прочего. Его задача — визуализировать использование стека и кучи.
Здесь вы можете увидеть, как исполняется вышеприведённая программа и как используются стек и куча:
Управление памятью JVM: сборка мусора
Давайте разберёмся с автоматическим управлением кучей, которое играет очень важную роль с точки зрения производительности приложения. Когда программа пытается выделить в куче больше памяти, чем доступно (в зависимости от значения Xmx ), мы получаем ошибки нехватки памяти.
JVM управляет куче с помощью сборки мусора. Чтобы освободить место для создания нового объекта, JVM очищает память, занятую потерянными объектами, то есть объектами, на которые больше нет прямых или опосредованных ссылок из стека.
Сборщик мусора в JVM отвечает за:
Сборщик мусора Mark & Sweep
JVM использует отдельный поток демона, который работает в фоне для сборки мусора. Этот процесс запускается при выполнении определённых условий. Сборщик Mark & Sweep обычно работает в два этапа, иногда добавляют третий, в зависимости от используемого алгоритма.
JVM предлагает на выбор несколько разных алгоритмов сборки мусора, и в зависимости от вашего JDK может быть ещё больше вариантов (например, сборщик Shenandoah в OpenJDK). Авторы разных реализаций стремятся к разным целям:
Сборщики в JDK 11
Процесс сборки мусора
Вне зависимости от того, какой выбран сборщик, в JVM используется два вида сборки — младший и старший сборщик.
Младший сборщик
Он поддерживает чистоту и компактность пространства молодого поколения. Запускается тогда, когда JVM не может получить в раю необходимую память для размещения нового объекта. Изначально все области кучи пусты. Рай заполняется первым, за ним область выживших, и в конце хранилище.
Здесь вы можете увидеть процесс работы этого сборщика:
Старший сборщик
Следит за чистотой и компактностью пространства старого поколения (хранилищем). Запускается при одном из таких условий:
Заключение
Мы рассмотрели структуру и управление памятью JVM. Это не исчерпывающая статья, мы не говорили о многих более сложных концепциях и способах настройки под особые сценарии использования. Подробнее вы можете почитать здесь.
Но для большинства JVM-разработчиков (Java, Kotlin, Scala, Clojure, JRuby, Jython) этого объёма информации будет достаточно. Надеюсь, теперь вы сможете писать более качественный код, создавать более производительные приложения, избегая различных проблем с утечкой памяти.
Распределение памяти в JVM
Всем привет! Перевод сегодняшнего материала мы хотим приурочить к запуску нового потока по курсу «Разработчик Java», который стартует уже завтра. Что ж начнём.
JVM может быть сложным зверем. К счастью, большая часть этой сложности скрыта под капотом, и мы, как разработчики приложений и ответственные за деплой, часто не должны об этом сильно беспокоиться. Хотя из-за роста популярности технологий развертывания приложений в контейнерах, стоит обратить внимание на распределение памяти в JVM.
Как вы видите, на память вне кучи приходится большая часть используемой памяти JVM, причем память кучи составляет только одну шестую часть от общего объёма. В этом случае это примерно 44 МБ (из которых 33 МБ использовалось сразу после сборки мусора). Использование памяти вне кучи составило в сумме 223 МБ.
Области нативной памяти
Отсюда:
If UseCompressedOops is turned on and UseCompressedClassesPointers is used, then two logically different areas of native memory are used for class metadata…
A region is allocated for these compressed class pointers (the 32-bit offsets). The size of the region can be set with CompressedClassSpaceSize and is 1 gigabyte (GB) by default…
The MaxMetaspaceSize applies to the sum of the committed compressed class space and the space for the other class metadata
Для сжатых указателей выделяется область памяти (32-битные смещения). Размер этой области может быть установлен CompressedClassSpaceSize и по умолчанию он 1 ГБ…
Параметр MaxMetaspaceSize относится к сумме области сжатых указателей и области для других метаданных класса.
По сравнению с кучей, память вне кучи меньше изменяется под нагрузкой. Как только приложение загрузит все классы, которые будут использоваться и JIT полностью прогреется, всё перейдет в устойчивое состояние. Чтобы увидеть уменьшение использования области Compressed class space, загрузчик классов, который загрузил классы, должен быть удален сборщиком мусора. Это было распространено в прошлом, когда приложения развертывались в контейнерах сервлетов или серверах приложений (загрузчик классов приложения удалялся сборщиком мусора, когда приложение удалялось с сервера приложений), но с современными подходами к развертыванию приложений это случается редко.
Интересной областью памяти JVM является кэш кода JIT. По умолчанию HotSpot JVM будет использовать до 240 МБ. Если кэш кода слишком мал, в JIT может не хватить места для хранения своих данных, и в результате будет снижена производительность. Если кэш слишком велик, то память может быть потрачена впустую. При определении размера кэша важно учитывать его влияние как на использование памяти, так и на производительность.
При работе в контейнере Docker последние версии Java теперь знают об ограничениях памяти контейнера и пытаются соответствующим образом изменить размер памяти JVM. К сожалению, часто происходит выделение большого количества памяти вне кучи и недостаточного в куче. Допустим, у вас есть приложение, работающее в контейнере с 2-мя процессорами и 512 МБ доступной памяти. Вы хотите, чтобы обрабатывалось больше нагрузки и увеличиваете количество процессоров до 4-х и память до 1 ГБ. Как мы обсуждали выше, размер кучи обычно изменяется в зависимости от нагрузки, а память вне кучи изменяется значительно меньше. Поэтому мы ожидаем, что большая часть дополнительных 512 МБ будет предоставлена куче, чтобы справиться с увеличенной нагрузкой. К сожалению, по умолчанию JVM этого не сделает и распределит дополнительную память более менее равномерно между памятью в куче и вне кучи.
К счастью, команда CloudFoundry обладает обширными знаниями о распределении памяти в JVM. Если вы загружаете приложения в CloudFoundry, то сборщик (build pack) автоматически применит эти знания для вас. Если вы не используете CloudFoudry или хотели бы больше понять о том, как настроить JVM, то рекомендуется прочитать описание третьей версии Java buildpack’s memory calculator.
Что это значит для Spring
Команда Spring проводит много времени, думая о производительности и использовании памяти, рассматривая возможность использования памяти как в куче, так и вне кучи. Один из способов ограничить использование памяти вне кучи — это делать части фреймворка максимально универсальными. Примером этого является использование Reflection для создания и внедрения зависимостей в бины вашего приложения. Благодаря использованию Reflection количество кода фреймворка, который вы используете, остается постоянным, независимо от количества бинов в вашем приложении. Для оптимизации времени запуска мы используем кэш в куче, очищая этот кэш после завершения запуска. Память кучи может быть легко очищена сборщиком мусора, чтобы предоставить больше доступной памяти вашему приложению.
Традиционно ждём ваши комментарии по материалу.
Увеличение использования памяти для JAVA в JIRA
Рассмотрим еще одну полезную настройку в работе Jira Service Desk.
По мере увеличения числа сотрудников, которые будет работать в JIRA, Вы будете замечать или будут поступать обращения о том, что как-то медленно все работает. Это связанно с тем, что продукт Jira Service Desk написан на JAVA. Загрузку JAVA по памяти можно увидеть в Администрирование — Система — Системная информация — Статистика памяти Java Virtual Machine
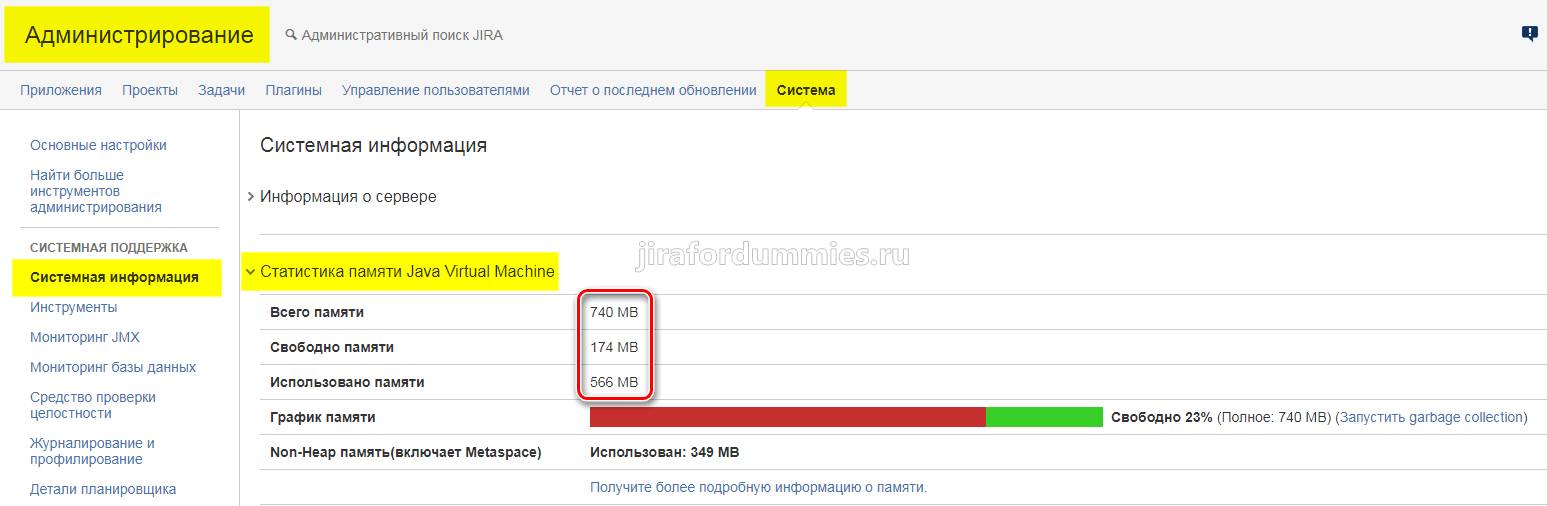
По умолчанию во время инсталляции продукта для JAVA выделен жестко объем памяти в диапазоне от 384 МБ до 768 МБ.
Это можно увидеть в файле /opt/atlassian/jira/bin/setenv.sh
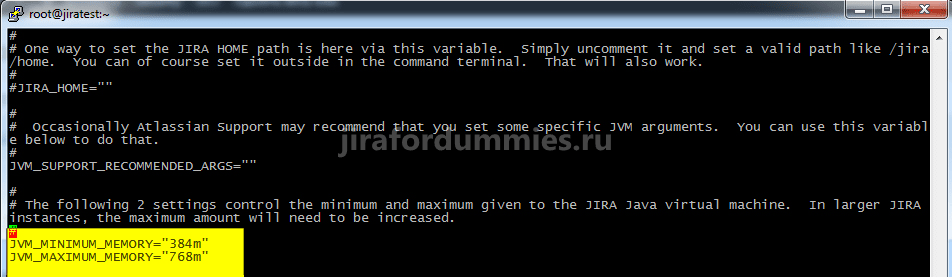
Учитывая, что на этапе создания виртуальной машины, мы выделили серверу 8 Гб памяти, то отредактируем файл и дадим JAVA максимум 7 Гб. Открываем файл командой
и перейдя в режим редактирования нажатием на клавишу A изменим параметр JVM_MINIMUM_MEMORY на 1024m, а параметр JVM_MAXIMUM_MEMORY на 7168m.
После чего нажав на клавишу ESC, выходим из режима редактирования и выходим их файла сохранив изменения командой :wq!
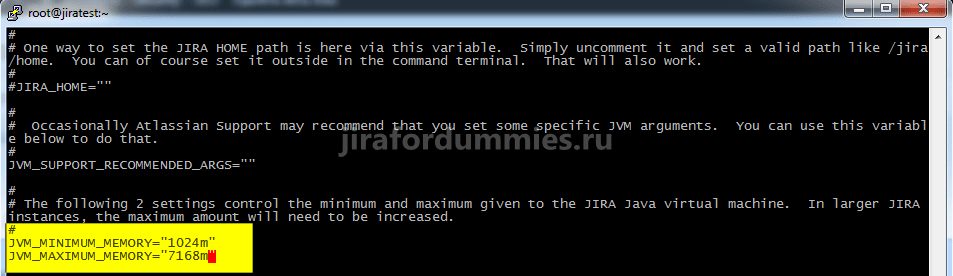
Для вступления изменений в силу, необходимо перезапустить службу jira следующими командами
дожидаемся остановки и запускаем службу
Минут через 3-5 минут заходим в Администрирование — Система — Системная информация — Статистика памяти Java Virtual Machine и вот что мы увидим. Можно заодно запустить очистку памяти от ‘мусора‘ нажав на Запустить garbage collection.
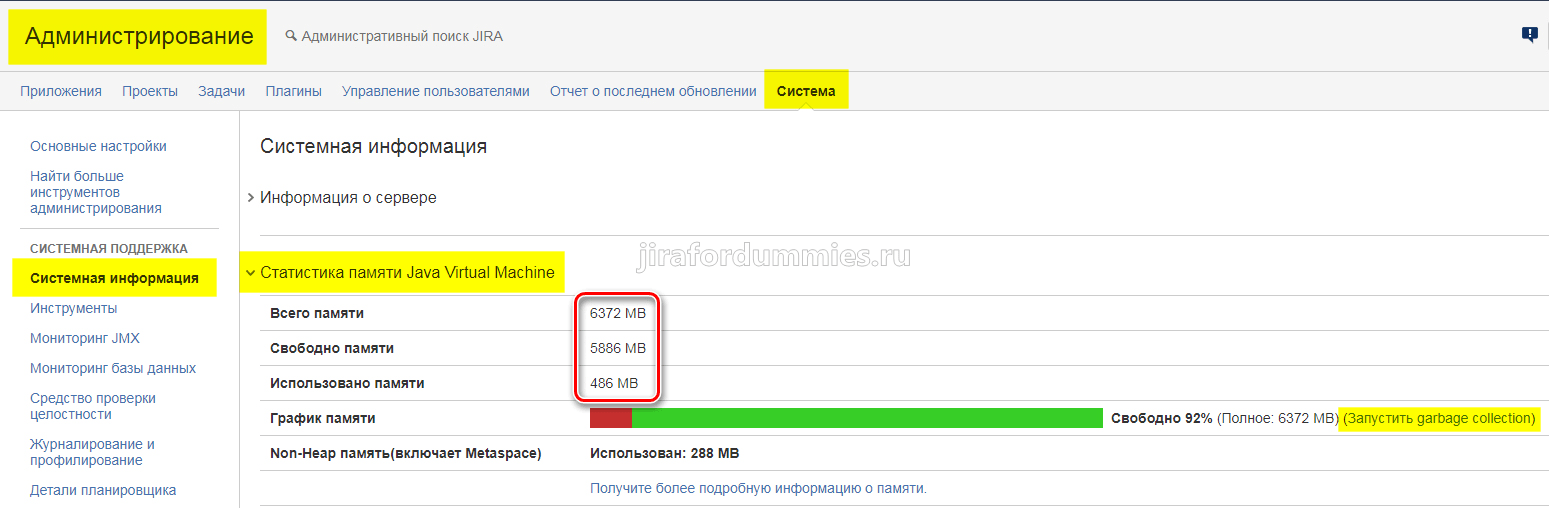
Сразу почувствуйте как JIRA стала шустрее работать.